什么是DOM?
DOM(Document Object Model)文档对象模型,是语言和平台的中立接口。。
允许程序和脚本动态地访问和更新文档的内容。
为什么要使用DOM?
Dom技术使得用户页面可以动态地变化,如可以动态地显示或隐藏一个元素,改变它们的属性,增加一个元素等,Dom技术使得页面的交互性大大地增强。
HTML的DOM
HTML的DOM是一个内存对象树,在浏览器中只保存一份,HTML的DOM修改HTML的内容会直接反应到浏览器中
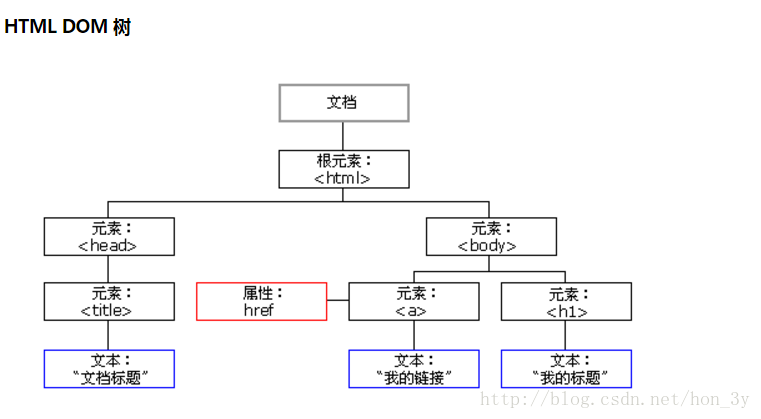
API
NODE对象API
在DOM眼中,HTML是由不同类型的节点组成的,这些节点都属性NODE对象。
NODE对象有一个nodeType的属性可用于判断节点类型

HTML不同类型的节点之间都是有联系的:
- 位于一个节点之上的节点是该节点的父节点(parent)
- 一个节点之下的节点是该节点的子节点(children)
- 同一层次,具有相同父节点的节点是兄弟节点(sibling)
- 一个节点的下一个层次的节点集合是节点后代(descendant)
- 父、祖父节点及所有位于节点上面的,都是节点的祖先(ancestor)
于是乎,NODE对象也有访问节点的属性和方法
属性:
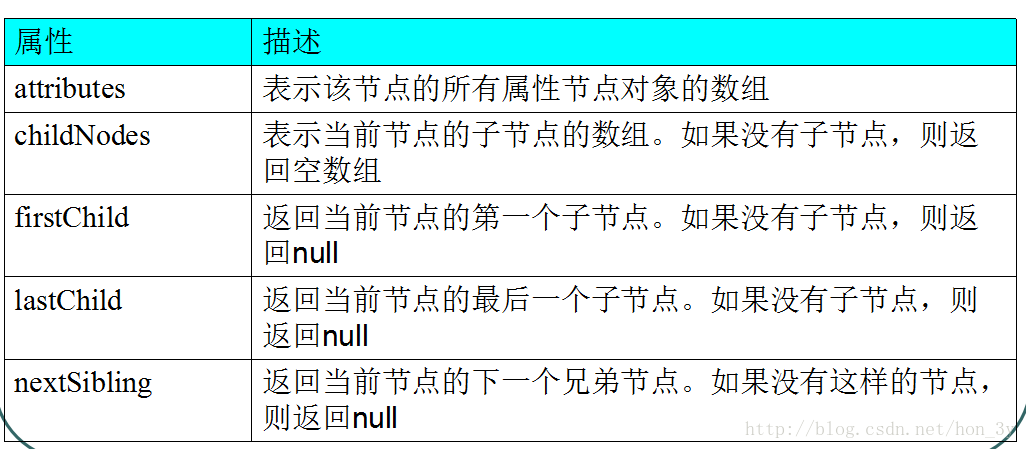
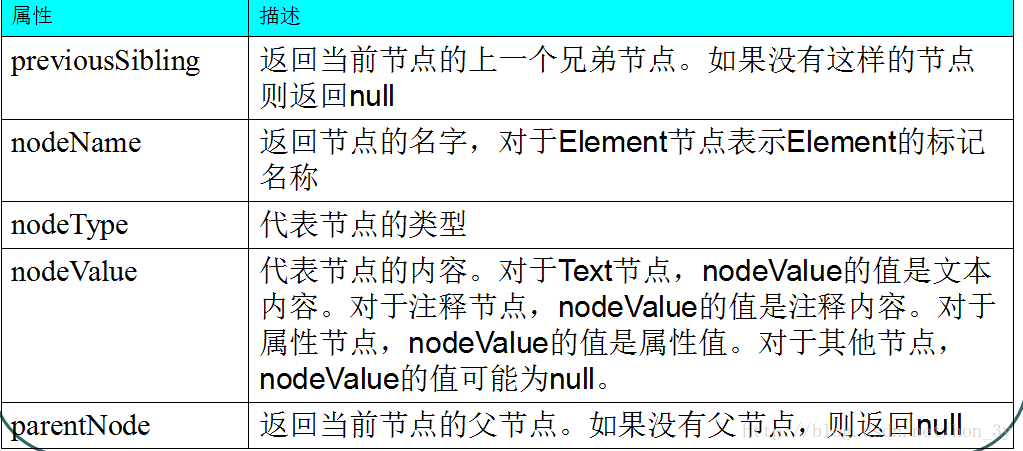
总的来说就是:得到节点的信息(节点名字、节点值)以及访问节点的兄弟、父亲
方法:
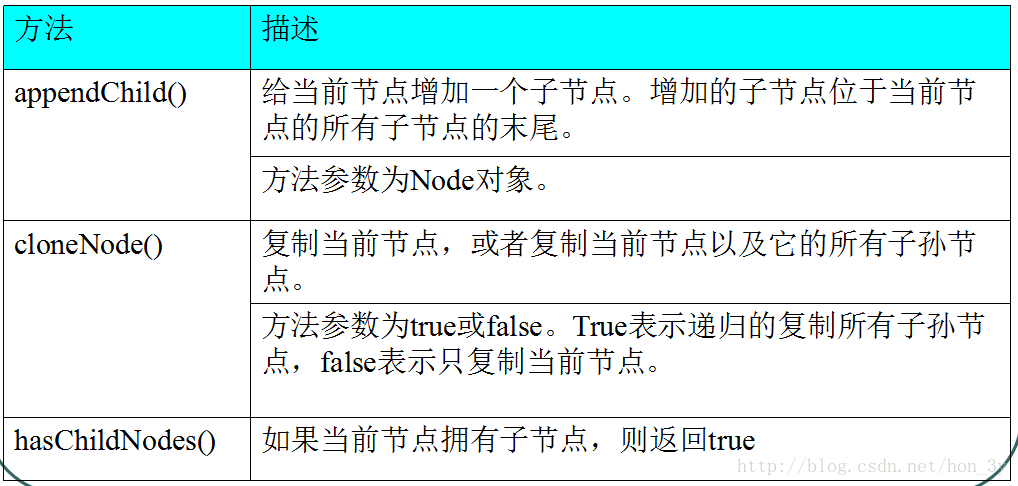

总的来说就是:添加、替换、删除子节点,判断是否有子节点,克隆子节点
document
HTML的DOM中我们提到并大量使用了document这个Javascirpt的内置对象,请注意这个对象仅仅可以表示HTML的根节点。
document的属性:
- documentElement【可以获取得到
<html>这个节点】
document方法:
- createElement()【创建一个元素节点】
- createComment()【创建注释】
- createAttribute()【创建属性节点】
- createTextNode()【创建文本节点】
- getElementById()【通过id得到该元素节点】
- getElementsByTagName()【通过标签名,得到所有标签名的数组】
Element接口
Element代表的是元素节点,是我们经常用到的一个接口!
Element属性:
- tagName【返回的是元素标签的大写名称】
Element方法:
- getAttribute(String name)【得到属性的值】
- setAttribute(String name,String value)【设置属性的名称和值,不存在则创建】
- getElementsByTabName()【返回该元素节点的子孙节点的数组】
- removeAttribute()【移除属性】
当我们设置属性的时候,我们不是调用方法来设置,而经常会这样做:
var input = document.createElement("input"); input.value = "aa"; input.name = "bb"; XML的DOM
我们可能会用XML文件作为客户端和服务器的传输文件。于是我们需要学习在JavaScript代码中通过DOM操作XML文档
XML和HTML的API是十分类似的,这里就不赘述了。
装载XML
客户端和服务端如果是通过XML文件或者XML字符串进行交互数据的话。那么,我们需要装载服务器的XML文件或XML字符串到JavaScript中的DOM对象。
现在问题就是,IE和fireFox的装载XML方式是不一样的。因此,我们最好封装成一个方法来装载XML。
/** * @param flag true代表的是文件,false代表的是字符串 * @param xmldoc 要封装成DOM对象的字符串或文件 * @return 返回的是根节点的元素节点 * 重点放在高版本上!! * */function loadXML(flag, xmldoc) { //浏览器是低版本的IE var objXml; if (window.ActiveXObject) { //是IE的话,有两种方式来创建ActiveXObject对象 var name = ["MSXML2.DOMDocument", "Miscrosoft.XmlDom"]; for (var i = 0; i < name.length; i++) { objXml = new ActiveXObject(name); break; } //设置为同步【装载XML文件成DOM对象,我们都是同步操作】 objXml.async = false; //如果是字符串 if (flag == false) { objXml.loadXML(xmldoc); } else { //如果是文件 objXml.load(xmldoc) } return objXml.documentElement; //浏览器是fireFox或者高版本的IE } else if (document.implementation.createDocument) { //字符串 if (flag == false) { //创建对象,解析XML字符串 objXml = new DOMParser(); //解析到根节点 var root = objXml.parseFromString(xmldoc, "text/xml"); return root.documentElement; } else { //由于安全问题,想要得到XML文件,需要通过XMLHttpRequest对象来获取 objXml = new XMLHttpRequest(); //同步 objXml.open("GET", "1.xml", false); objXml.send(null); //返回XML数据 return objXml.responseXML.documentElement; } //解析不了啦 } else { alert("解析不了了"); }} 测试

去除空白字符
如果有需要就加这段功能吧!
function removeBlank(xml) { if (xml.childNodes.length > 1) { for (var loopIndex = 0; loopIndex < xml.childNodes.length; loopIndex++) { var currentNode = xml.childNodes[loopIndex]; if (currentNode.nodeType == 1) { removeBlank(currentNode); } if (((/^\s+$/.test(currentNode.nodeValue))) && (currentNode.nodeType == 3)) { xml.removeChild(xml.childNodes[loopIndex--]); } } }} XPATH
XPATH技术其实我们已经接触过了,在讲解XML的时候,我们已经使用过了XPATH技术了。
可以参考我之前的XML博文:
XPATH总体可分为三种搜索:
- 绝对路径搜索(/根节点/子节点)
- 相对路径搜索(子节点/子节点)【与绝对路径搜索的差别就是开头有无"/"】
- 全文搜索(//子节点)
如果我们要查找属性节点、文本节点、多条件的节点是这样写XPATH的
- 属性节点:(先找到元素节点/@属性名)
- 文本节点:(先找到元素节点/test())
- 有条件查询节点:(先找到元素节点/[条件])
- 多条件查询节点:(先找到元素节点/[条件][条件])【两个条件同时吻合】
- 多条件查询节点:(先找到元素节点/[条件]|先找到元素节点/[条件])【或关系】
我们之前使用dom4j的时候,是调用selectSingleNode()和selectNodes()方法来获取任意深度的节点或多个节点
我们想要在JavaScript中使用XPATH技术,那么我们也实现这两个方法,调用它就行了!
selectSingleNode()
IE10,IE11下无法使用selectSingleNode()方法。解决参考:
但是,我没有解决掉该问题。。。。。
下面是JavaScript代码:
/** * * @param xmldoc 代表的是XML的根节点 * @param xpath 给出的XPATH表达式 * @return 返回的是对应的节点或多个节点 * * * */function selectSingleNode(xmldoc,xpath) { //如果是IE,IE10,IE11解决不了....会的人告诉我一声!! if(navigator.userAgent.indexOf(".NET")>0) { var value = xmldoc.selectNodes(xpath) return value; }else { //如果是fireFox var xpathObj = new XPathEvaluator(); var value = xpathObj.evaluate(xpath, xmldoc, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null); return value.singleNodeValue; }} - 测试代码:
- 在fireFox,Chrome浏览器可以正常获取得到节点
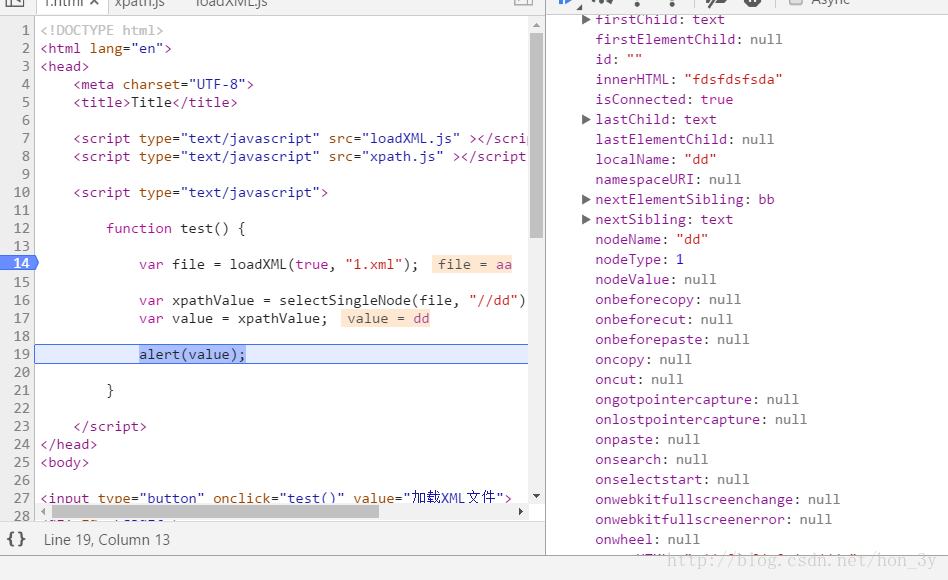
selectNodes()
由于上面IE问题我到现在还没有解决,所以下面直接测试FireFox浏览器了。
等我复习到Jquery的时候,再把这里的坑填了吧。。。
- javaScript代码:
/** * * @param xmldoc 代表的是XML的根节点 * @param xpath 给出的XPATH表达式 * @return 返回的是节点数组 */function selectNodes(xmldoc,xpath) { var xpathObj = new XPathEvaluator(); //如果是多节点,返回的是迭代器 var iterator = xpathObj.evaluate(xpath, xmldoc, null, XPathResult.ORDERED_NODE_ITERATOR_TYPE, null); //把迭代器的数据写到数组中 var arr = new Array(); var node; while ((node=iterator.iterateNext())!=null) { arr.push(node); } return arr;} - 测试代码:
function test() { var file = loadXML(true, "1.xml"); var xpathValue = selectNodes(file, "//aa"); var value = xpathValue; alert(value); } - 效果:
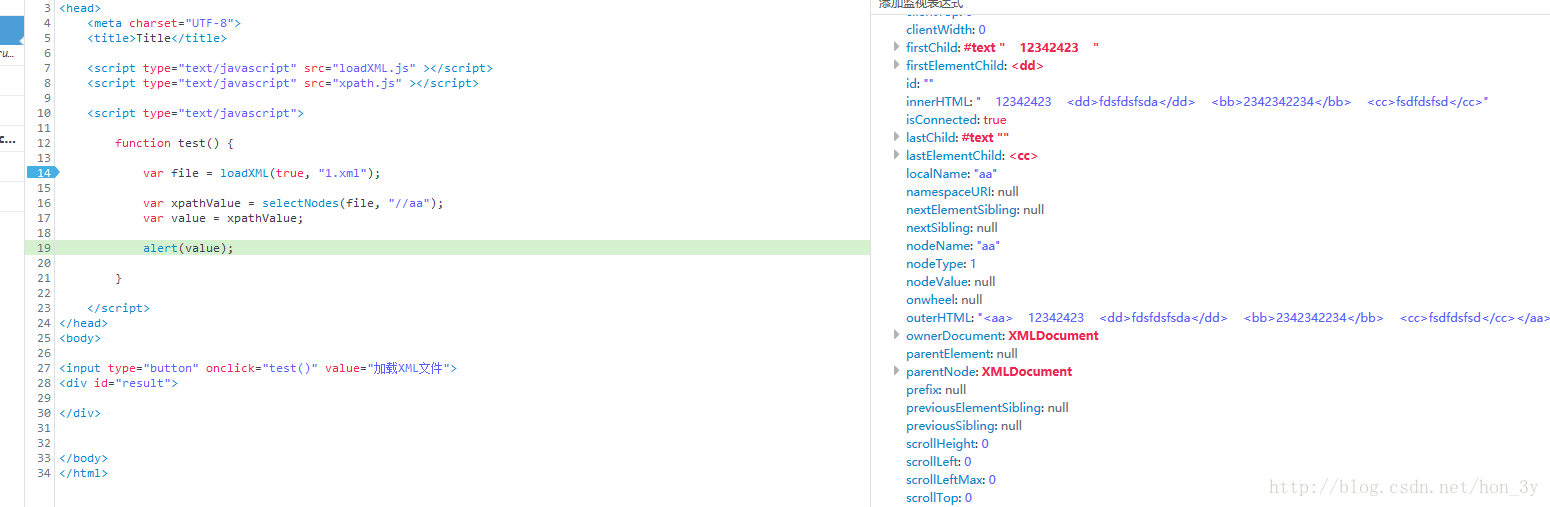
如果文章有错的地方欢迎指正,大家互相交流。习惯在微信看技术文章,想要获取更多的Java资源的同学,可以关注微信公众号:Java3y